Lokales LLM mit ollama
Installieren und Benutzen von ollama - Ein Leitfaden für lokale LLMs
11.06.2025
•9 Min. LesezeitInstallieren und Benutzen von ollama: Ein Leitfaden für lokale LLMs
Einführung
In diesem Beitrag geht es darum, wie man ein lokales Large Language Modell (LLM) auf seinem eigenen PC starten kann. Wenn man einen halbwegs modernen Computer hat, sollte das auch in der Regel gut klappen. Die Hardwareanforderungen findet ihr weiter im nächsten Abschnitt.
Warum sollte man ein lokales LLM aufsetzen?
- Man braucht keine Internetverbindung beim Benutzen des LLMs
- Man kann sich sicher sein, dass die eigenen Daten nicht zum Training eines LLMs genutzt werden. Im Falle, dass man vertrauliche Daten mit dem LLM bearbeitet / analysiert.
- Man kann unterschiedliche OpenSource LLMs einsetzen und ausprobieren und auch evaluieren.
- Man kann es für private Coding Assistenten einsetzen
- Man kann es für private RAG Systeme einsetzen
Dies sind nur einige der vielen Einsatzmöglichkeiten für lokale LLMs.
Nun möchte ich zum eigentlichen Thema kommen: Wie setze ich ein lokales LLM auf. Hierzu möchte ich das Tool ollama einsetzen, das einfach zu installieren und benutzen ist. Ich muss erwähnen, dass es sich hierbei um eine CLI (Command Line Interface) - sprich Kommandozeilen - Anwendung handelt. Des Weiteren kann man über ollama auch eine REST API zur Verfügung stellen, die man dann mit eigenen Apps anspricht oder andere OpenSource Anwendungen darüber laufen lässt.
Hardwareanforderungen
Ich benutze seit vielen Jahren schon ein Apple Gerät, daher werde ich die Aussagen auch nur für einen Mac machen.
- Betriebssystem: macOS 11 Big Sur oder neuer
- Prozessor: Ein Prozessor mit Apple Silicon wird empfohlen, wobei es auch Berichte darüber gibt, dass es auch auf einem Intel-Prozessor funktioniert (Quelle: Reddit).
- Arbeitsspeicher (RAM):
- Mindestens 8 GB RAM für 7B-Modelle
- 16 GB RAM für 13B-Modelle
- 32 GB RAM für größere Modelle wie 33B
- Speicherplatz: Mindestens 50 GB freier Speicherplatz wird empfohlen, da die Modelle selbst mehrere Gigabyte groß sein können.
- GPU: Auf Macs mit Apple Silicon (M1/M2/M3 Chips) wird die integrierte GPU genutzt.
- Für optimale Leistung, insbesondere bei größeren Modellen, wird empfohlen:
- Neuere Mac-Modelle mit Apple Silicon (M1/M2/M3) zu verwenden
- Möglichst viel RAM zur Verfügung zu stellen
- Ausreichend Speicherplatz für die Modelle und generierten Daten bereitzustellen
Installation auf Mac
- Öffnen Sie den Browser und gehen Sie zur offiziellen ollama-Website.
- Laden Sie die Mac-Version von ollama herunter.
- Öffnen Sie die heruntergeladene Datei und folgen Sie den Installationsanweisungen.
- Nach der Installation öffnen Sie das Terminal.
- Geben Sie "ollama run llama3.1" ein, um das Llama LLM in der Version 3.1 zu laden und zu starten. Mehr Infos zum Modell findet ihr hier: llama3.1
Benutzung von ollama
Nach der Installation können Sie ollama wie folgt verwenden:
- Öffnen Sie das Terminal auf ihrem Mac.
- Um ein Modell zu laden und zu starten, geben Sie ein:
ollama run llama2
Beim ersten Ausführen von diesem Befehl kann es etwas länger dauern, da das Modell zunächst heruntergeladen werden muss. Abhängig von der Modellgröße und ihrer Internetgeschwindigkeit, kann es kürzer oder länger dauern. Bleiben Sie geduldig 😊
Wenn der Download des Modells fertig ist, sollten Sie so etwas in ihrem Terminal sehen:
pulling manifest
pulling 8eeb52dfb3bb... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 4.7 GB
pulling 948af2743fc7... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling 0ba8f0e314b4... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 12 KB
pulling 56bb8bd477a5... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 96 B
pulling 1a4c3c319823... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
Nun können Sie mit dem Modell chatten. Zum Beispiel könnten Sie folgendes fragen:
>>> Was sind die 4 Jahreszeiten? Erkläre mir das als wäre ich ein 5 jähriger
Weitere Funktionen von ollama
Lokale Modelle anzeigen
Um die lokalen Modelle anzuzeigen, kann man diesen Befehl benutzen:
$ ollama list
NAME ID SIZE MODIFIED
llama3.1:latest 42182419e950 4.7 GB 8 minutes ago
Da wir eine frische Installation von ollama haben und nur ein Modell heruntergeladen haben, sehen wir auch nur einen Eintrag.
Informationen zu lokalen Modellen
Um mehr Informationen zu einem lokalen Modell zu erhalten, kann man diesen Befehl benutzen:
$ ollama show llama3.1
Model
parameters 8.0B
quantization Q4_0
arch llama
context length 131072
embedding length 4096
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024
In diesem Beispiel sehen wir, dass es sich hierbei um ein 8B (Billion) Parameter Modell handelt und dass es auf der llama Architektur basiert ... verrät ja schon der Name 😄.
Aber so kann man sich die notwendigen Infos anzeigen lassen und prüfen ob sie zum Anwendungsfall auch passen.
Herunterladen von weiteren Modellen
ollama unterstützt nicht alle Modelle, die in der LLM OpenSource Community vorhanden sind. Eine Übersicht über die in ollama verfügbaren Modelle findet man in der Library von ollama.
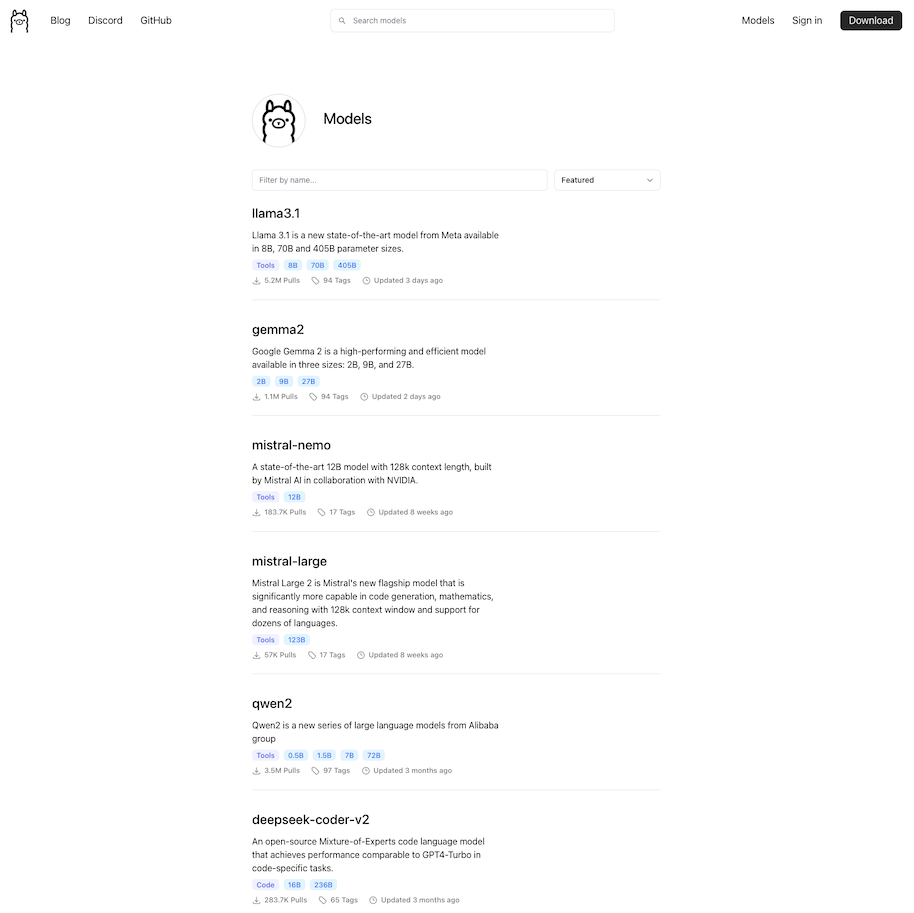 In dem Screenshot sieht man einen kleinen Teil der verfügbaren Modelle. Um jetzt ein Modell herunter zu laden führt man diesen Befehl aus:
In dem Screenshot sieht man einen kleinen Teil der verfügbaren Modelle. Um jetzt ein Modell herunter zu laden führt man diesen Befehl aus:
$ ollama pull gemma2
In diesem Beispiel lade ich das Google Modell gemma2 runter. Falls man noch eine Auswahl der Parameter mit angeben möchte, macht man das so, Infos wie der Befehl aussehen muss um die richtige Parametergröße zu bekommen findet man hier:
$ ollama pull gemma2:2b
API zur Verfügung stellen
Wenn man jetzt nicht nur über die CLI chatten möchte, sondern weitere Anwendungen auf das LLM zugreifen sollen, muss eine API zur Verfügung gestellt werden. Dies erreicht man über diesen Befehl:
$ ollama serve
In der Regel startet die API automatisch, wenn man die Desktop App startet. Falls die ollama Desktop App schon läuft, sehen Sie diese Nachricht:
$ Error: listen tcp 127.0.0.1:11434: bind: address already in use
Trotz dieser Fehlermeldung können Sie einen CURL-Request senden, um die Funktionalität zu überprüfen. Zum Beispiel diesen hier:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "Was sind die 4 Jahreszeiten? Erkläre mir das als wäre ich ein 5 jähriger",
"stream": false
}'
Und so sollte das Ergebnis aussehen:
{
"model":"llama3.1",
"created_at":"2024-09-18T18:52:35.80851Z",
"response":"Die 4 Jahreszeiten sind:\n\n1. **Frühling**: Der Frühling ist eine schöne Zeit! Die Sonne wird wieder stärker, und es wird immer wärmer. Die Bäume und Büsche bekommen Grünblätter, und die Blumen beginnen zu blühen. Es gibt viele schöne Farben und Gerüche in der Natur!\n2. **Sommer**: Im Sommer ist es oft sehr warm und sonnig! Man kann sich gerne im Sand oder am Wasser tummeln. Die Tage sind lang, und man hat viel Zeit, sich zu unterhalten. Es ist eine tolle Zeit für Picknicks, Spielplatz-Besuche und viele andere Freuden!\n3. **Herbst**: Im Herbst wird es wieder kälter und rauer. Die Blätter an den Bäumen beginnen zu fallen, und die Natur bekommt ein bisschen Farbe in Gold, Orange und Rot. Es ist eine schöne Zeit für Spaziergänge und fürs Sammeln von Nuss- oder Apfelabfällen!\n4. **Winter**: Im Winter ist es oft sehr kalt! Die Sonne ist nicht so stark, und man sollte sich warm anziehen, wenn er draußen ist. Es gibt viel Schnee und Eis, und viele Kinder genießen den Schlittenfahren! Es ist auch eine gute Zeit für Indoor-Spiele und Freizeitaktivitäten.\n\nJede Jahreszeit hat ihre eigene Schönheit und Möglichkeiten zum Spielen und Entspannen!",
"done":true,
"done_reason":"stop",
"context":[
128006,882,128007,271,27125,12868,2815,220,19,98848,3059,15010,30,9939,10784,47786,8822,6754,10942,69673,10864,4466,220,20,503,38056,7420,128009,128006,78191,128007,271,18674,220,19,98848,3059,15010,12868,1473,16,13,3146,23376,22284,2785,96618,13031,2939,22284,2785,6127,10021,92996,29931,0,8574,12103,818,15165,27348,357,14304,7197,11,2073,1560,15165,26612,289,14304,1195,13,8574,426,2357,3972,2073,69657,82,1557,75775,2895,16461,2067,14360,466,11,2073,2815,2563,28999,3240,12778,6529,1529,2448,12301,13,9419,28398,43083,92996,13759,8123,2073,20524,2448,1557,304,2761,40549,4999,17,13,3146,50982,1195,96618,2417,80609,6127,1560,43146,26574,8369,2073,4538,77,343,0,2418,16095,9267,55164,737,8847,12666,1097,74894,15756,76,17912,13,8574,72277,12868,8859,11,2073,893,9072,37177,29931,11,9267,6529,22229,36605,13,9419,6127,10021,39674,273,29931,7328,20305,77,5908,11,32480,58648,7826,288,34927,2073,43083,34036,7730,61227,4999,18,13,3146,21364,25604,96618,2417,6385,25604,15165,1560,27348,597,30902,466,2073,436,28196,13,8574,2563,14360,466,459,3453,426,2357,28999,3240,12778,6529,21536,11,2073,2815,40549,94177,2562,4466,293,1056,7674,13759,1395,304,7573,11,22725,2073,28460,13,9419,6127,10021,92996,29931,7328,3165,1394,1291,70,77241,2073,7328,82,8388,76,17912,6675,452,1892,12,12666,5345,59367,370,69,33351,268,4999,19,13,3146,67288,96618,2417,20704,6127,1560,43146,26574,597,3223,0,8574,12103,818,6127,8969,779,38246,11,2073,893,52026,9267,8369,459,13846,12301,11,22850,2781,45196,84,27922,6127,13,9419,28398,37177,5124,34191,2073,97980,11,2073,43083,45099,83857,27922,3453,50379,23257,98022,0,9419,6127,11168,10021,63802,29931,7328,64368,6354,20898,273,2073,7730,553,275,74707,65421,2002,382,41,15686,98848,30513,9072,35849,35834,1994,5124,24233,23190,2073,67561,52807,16419,20332,8564,2073,4968,1508,12778,0
],
"total_duration":10083803708,
"load_duration":31196166,
"prompt_eval_count":33,
"prompt_eval_duration":283579000,
"eval_count":328,
"eval_duration":9767887000
}
Wie wir sehen, erhalten wir über die API wesentlich mehr Informationen als über den Chat. Wenn wir jetzt die Geschwindigkeit (Token / Sekunde) berechnen wollen, müssten wir folgende Rechnung aufmachen:
eval_count / eval_duration * 10^9
eval_countist die Größe der Antwort in Tokens. Ein Token ist in der Regel mehr als ein Buchstabe.eval_durationvergangene Zeit in Nanosekunden
So ergibt sich eine Geschwindigkeit von 33.57 Tokens pro Sekunde.
Weitere Informationen zu der ollama REST API gibt es hier auf dem ollama Github Projekt.
Zusammenfassung
In diesem Tutorial haben Sie gesehen, wie Sie ollama auf Ihrem Mac einrichten und benutzen können. Ich habe den einfachen Chat über die Kommandozeile vorgestellt und wie Sie die API ansprechen können. Darüber hinaus haben Sie ein paar elementare Funktionen von ollama kennengelernt.
Nun sind Sie dran, setzen Sie Ihr lokales LLM auf und chatten Sie drauf los!